ローカルで動くAIコーディング環境、気になりませんか?
僕は気になります。めっちゃ気になっています。
Claude Code や Cursor は便利ですが、月額料金がかかりますし。
そもそもコードをクラウドに送るのがちょっと……という場面もありますよね。
落合陽一さんが公開した vibe-local を使えば、ネットワーク不要・完全無料・オフラインで動く AIコーディングエージェントが手に入る?となり、早速インストールしました。
しかもインストールはコマンド1行。
MacBook Pro M4 Pro(メモリ24GB)で実際に動かしてみたので、セットアップの様子をスクリーンショット付きでお伝えします。
vibe-local ってなに?
vibe-local は、落合陽一さんのチームが公開したオープンソースのAIコーディングエージェントです。
特徴をざっくりまとめると、こんな感じ。
- 完全ローカル — コードもプロンプトも外部に送信しない
- 完全無料 — クラウドAPIの課金なし
- オフラインOK — インストール後はネットワーク不要
- ワンライナーインストール — curl 1行で全部入る
- Ollama + qwen3 — ローカルLLMを自動でセットアップ
Claude Code に似たインターフェースで、ファイルの読み書き、Bash実行、Git管理、ウェブ検索まで16個のツールが使えます。
動作環境:MacBook Pro M4 Pro(メモリ24GB)
今回インストールした環境です。
- マシン: MacBook Pro M4 Pro
- メモリ: 24GB
- OS: macOS
vibe-local はメモリ搭載量に応じて最適なモデルを自動選択してくれます。
| メモリ | メインモデル | サイドカー |
|---|---|---|
| 96GB以上 | gpt-oss:120b | qwen3-coder:30b |
| 32GB以上 | qwen3-coder:30b | qwen3:8b |
| 16GB〜24GB | qwen3:8b | qwen3:1.7b |
| 8GB | qwen3:1.7b | なし |
24GBの場合は qwen3:8b がメインモデル、qwen3:1.7b がサイドカー(軽量タスク用)になります。
インストール手順:コマンド1行で完了
ターミナルで1行実行するだけ
curl -fsSL https://raw.githubusercontent.com/ochyai/vibe-local/main/install.sh | bashこれだけです。あっ、ほんまにこれだけでした。かんたんです。
実行すると、VIBE LOCAL のアスキーアートがドーンと表示されて、「ネットワーク不要 • 完全無料 • ローカルAIコーディング」のメッセージが出ます。
かっこいい。
インストールの進行を追ってみる
STEP 1/7: システムスキャン
まず環境を自動検出します。
- OS: Darwin(macOS)
- Arch: arm64
- Apple Silicon Mac 検出 →「最適な環境です」
STEP 2/7: メモリ分析
搭載メモリを確認して、最適なモデルを自動選択。
- 搭載メモリ:24GB
- 推奨モデル:qwen3:8b(8GB、高性能コーディング)
- サイドカー:qwen3:1.7b(1.1GB、fast helper)
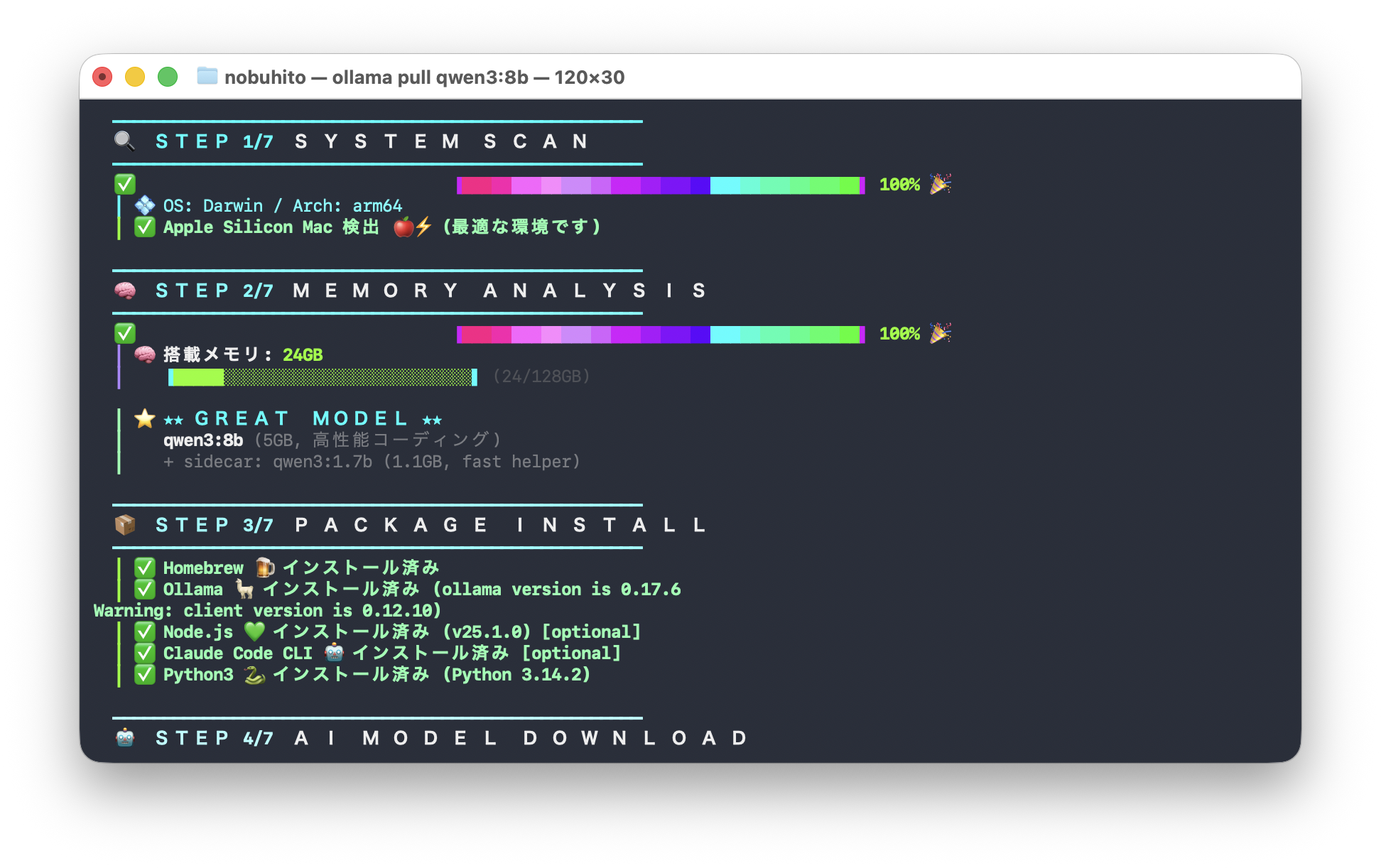
STEP 3/7: パッケージインストール
必要なツールを自動でインストール・確認してくれます。
- Homebrew → インストール済み
- Ollama → インストール済み(version 0.17.6)
- Node.js → インストール済み(v25.1.0)
- Claude Code CLI → インストール済み(optional)
- Python3 → インストール済み(Python 3.14.2)
すでに入っているものはスキップしてくれるので、既存の環境を壊す心配がありません。ほっ。
STEP 4/7: AIモデルダウンロード
ここが一番時間がかかるところです。qwen3:8b のモデルをダウンロードします。
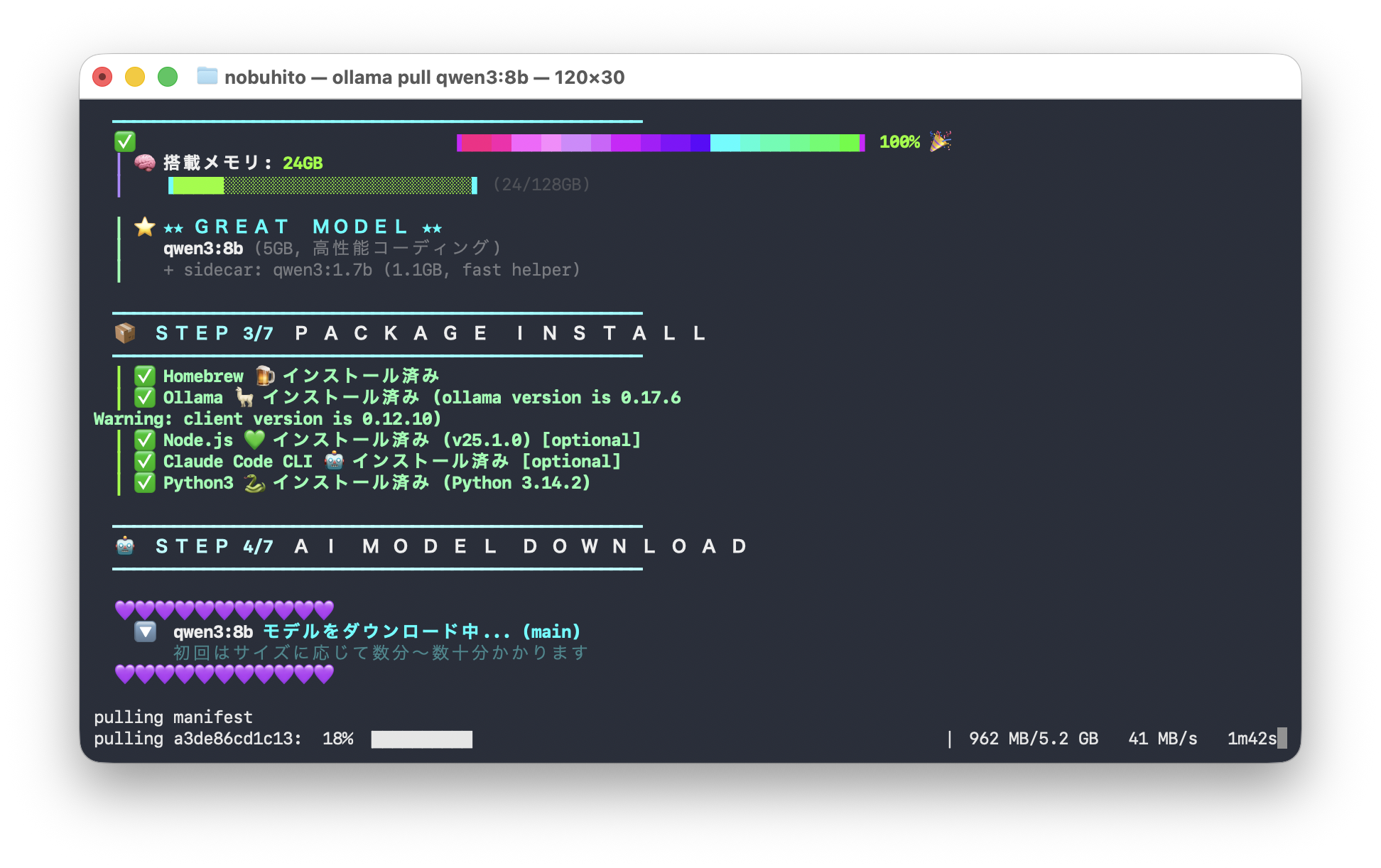
モデルサイズは 約5.2GB。うちの環境では数分〜十数分かかりました。ここだけはネットワーク接続が必要です。一度ダウンロードしたら、以降はオフラインで動きます。
起動してみる
インストールが終わったら、プロジェクトフォルダに移動して vibe-local を実行します。
cd your-project
vibe-localパーミッション確認
初回起動時にパーミッションの確認が出ます。
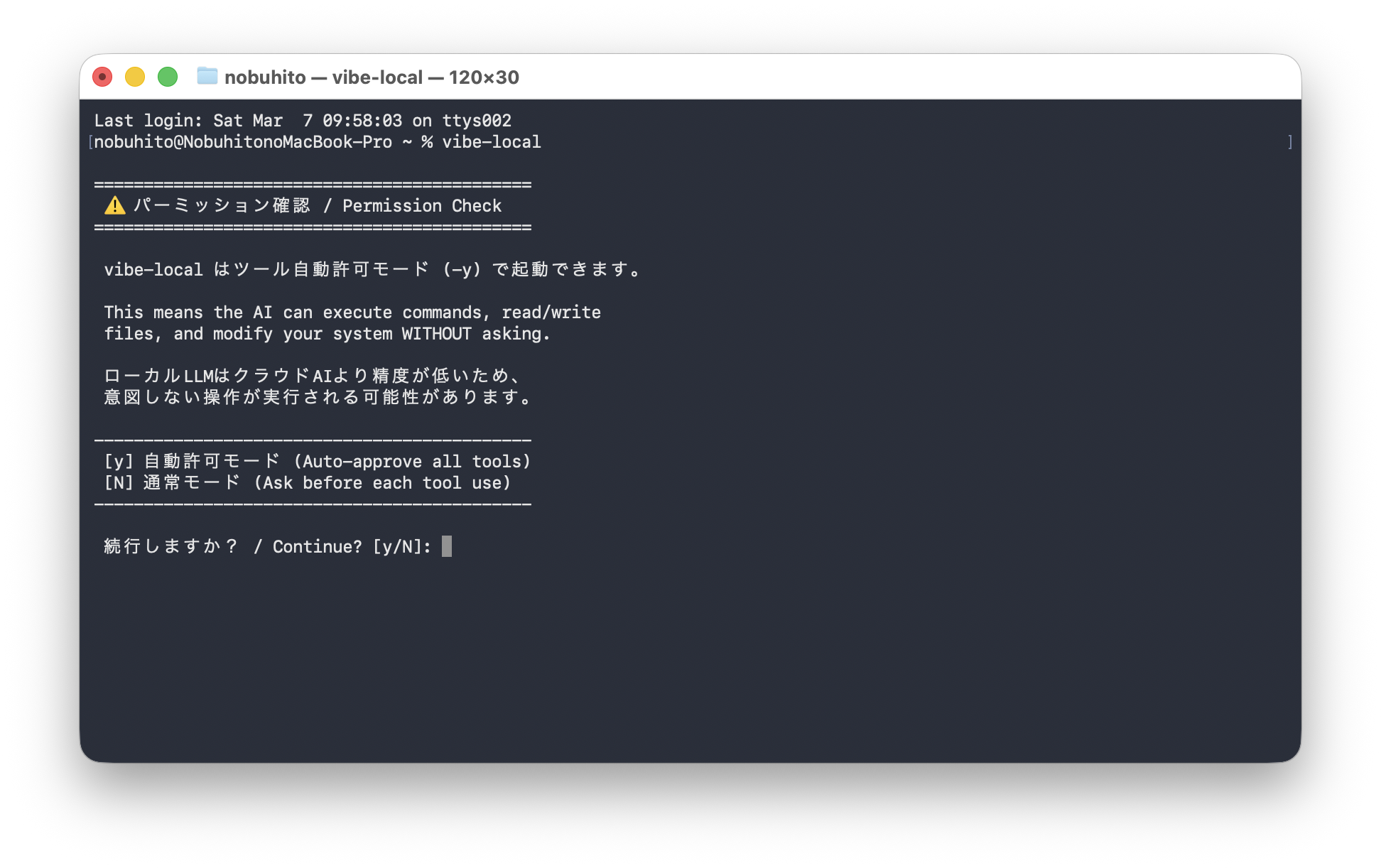
- [y] 自動許可モード — AIがコマンドを自動実行(確認なし)
- [N] 通常モード — 毎回確認してから実行
ローカルLLMはクラウドのAIより精度が低いため、「意図しない操作が実行される可能性があります」と警告が出ます。
なので、 通常モード [N] で様子を見ながら使っています。
起動完了
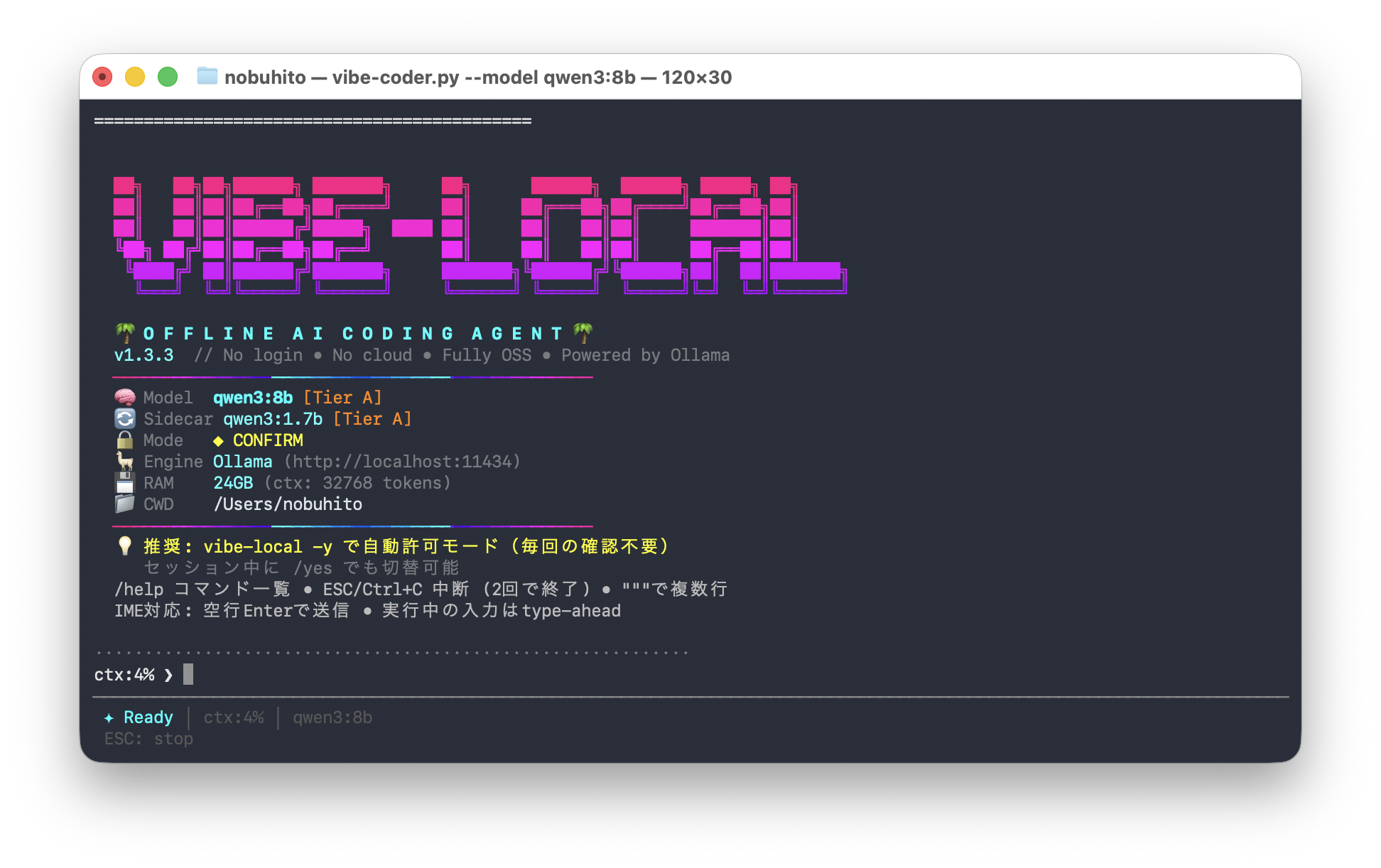
起動すると、こんな情報が表示されます。
- Model: qwen3:8b [Tier A]
- Sidecar: qwen3:1.7b [Tier A]
- Mode: CONFIRM
- Engine: Ollama (http://localhost:11434)
- RAM: 24GB(17,070 tokens)
- CWD: /Users/nobuhito
Claude Code に似たインターフェースで、プロンプトを入力するとAIがコードを書いてくれます。
使ってみた感想
よかったところ
インストールの簡単さが異常。 curl 1行で Ollama のインストールからモデルのダウンロードまで全部やってくれます。環境構築で詰まるストレスがゼロ。
オフラインで動く安心感。 機密性の高いプロジェクトや、飛行機の中でも使えます。コードがクラウドに送信されないのは大きい。
費用がゼロ。 Claude Code の月額や API 課金を気にせず、好きなだけ使えます。
気をつけるところ
ローカルLLMなので、Claude や GPT-4 と比べると精度は落ちます。 qwen3:8b は優秀ですが、複雑なリファクタリングや大規模なコード生成では差を感じる場面があります。
メモリ24GBだと、大きなプロジェクトでは少し厳しい場面も。 モデルがメモリを使うので、他のアプリと同時に使うときは注意が必要です。
自動許可モードは慎重に。 ローカルLLMの精度を考えると、通常モードで確認しながら使うのが安全です。
メモリ別のおすすめ
| メモリ | 体感 |
|---|---|
| 8GB | qwen3:1.7b のみ。簡単なタスクなら使える |
| 16GB〜24GB | qwen3:8b で実用レベル。ふだん使いに十分 |
| 32GB以上 | qwen3-coder:30b が使えて快適 |
| 96GB以上 | gpt-oss:120b でクラウドAIに近い体験 |
24GBあれば日常のコーディング支援には十分使える?のか?それは、これから様子を見ています。
まずは動きました。という感じです。
まとめ
落合陽一さんの vibe-local、MacBook Pro M4 Pro(24GB)で問題なく動きました。
- インストールは curl 1行 — 環境構築のストレスゼロ
- 完全無料・オフライン — API 課金なし、ネットワーク不要
- 24GBなら qwen3:8b が自動選択 — 実用レベルで動く
- Claude Code ライクなUI — 違和感なく使い始められる
- 精度はクラウドAIには及ばない — でもローカルで動く価値は大きい
Claude Code と使い分けるのがいいかなと思います。機密プロジェクトやオフライン環境では vibe-local、精度が求められる作業では Claude Code、という感じで。
お試しください。