
先行販売で、大阪 梅田 紀伊国屋さんにて、入手しました。

合計91の良質なインプットを実践するテクニックが満載の270ページ。最後に、参考・引用文献リストが掲載されているため、さらに学びを深めたいときの書籍へ繋げることができて、嬉しいです。
どのインプットテクニックも、「アウトプットを前提に行い、その効果を最大限に増幅させよ」とのメッセージが、突き刺さります。
特に、デジタルデータの扱い方についても、たくさんのページが割かれており、
- 探している情報を効率よくインプットするための検索テクニック
- 日々大量に受信するメールの扱い方
- ネットサーフィンを卒業するために、Google アラートやRSSリーダーの活用
など、『インプット大全』となっているタイトル通り、網羅した内容でした。
インプットを実践しているけれど、気がつけば時間が過ぎてしまっている、そんなあなたにピッタリな一冊です。
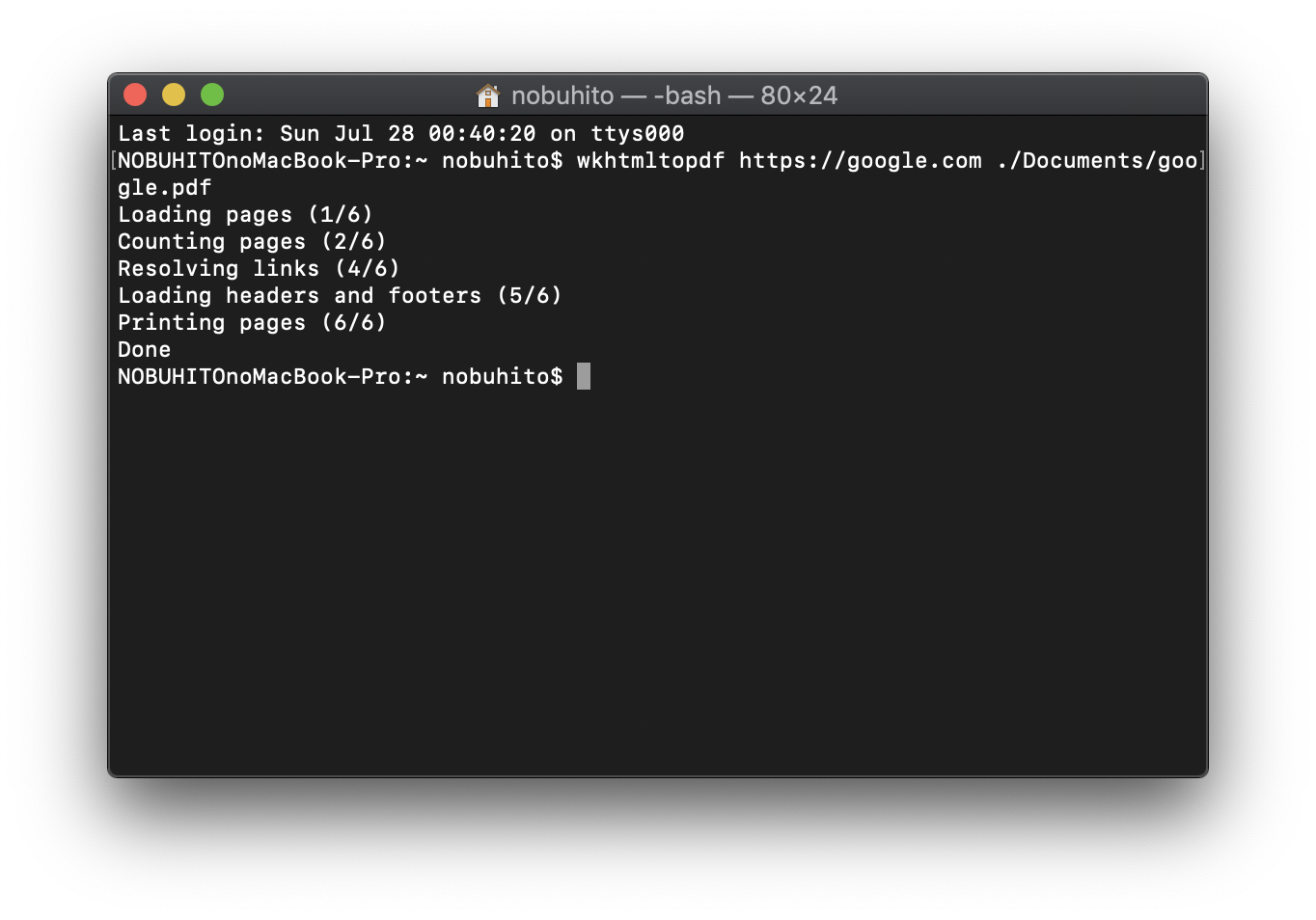
読んだ中で、一番響いたのが、「50 ストックする」で紹介されていた「ウェブ上の情報はPDFファイルで保存」でした。
今まで、Webの情報は、必要な時に、インタネットで再度検索して読み直すとしていましたが、PDFにしておけば、余計なネットサーフィンを止めることができるし、後からPDFファイルを、必要なカテゴリーごとにフォルダで整理し直して、情報を再構築することができます。
これは、梅棹 忠夫氏の『知的生産の技術』でも、語られています。もっとも、デジタルツールでなく、京大型情報カードでの形です。今はデジタルデータなので、本当に扱いやすくなっています。そして、Webページが1つのファイルになっているPDFでの保存方法を即実践することにしました。
とはいえ、単にプリントからPDFを作成すると、意外とWebページのレイアウトが崩れます。
レイアウト崩れや、大量にPDFを生成しても自動で整理できる環境を構築しました。詳しくは、こちらの下の記事で解説しています。
即実践できる素晴らしい一冊が『インプット大全』です。

![[ 日次クロージング 20130902 Vol. 82] 所要時間15時間56分 距離679.2km](https://mono96.jp/wp-content/uploads/2013/09/R0023425-1-150x150.jpg)


